Working with attributes in R (and QGIS)
Overview
Based on Ch. 3 Attribute data operations from Lovelace, Nowosad, and Muenchow (2022) we are going to look at the following:
What is attribute data?
How do you work with attribute data?
How do base R and dplyr compare for this work?
What is attribute data?
Attribute data is “non-spatial information associated with geographic (geometry) data.”
Most often, when we talk about attribute data we are talking about vector attribute data.
What can you do with attribute data?
You can…
- subset or filter data
- aggregate or summarize data
- combine data sets based on shared attributes
- create new attributes
Using R to work with attribute data
Loading packages
First, you should load the {sf}, {dplyr}, and {ggplot2} packages along with data from the {spData} package:
Then we can take a quick look at the attributes:
GEOID NAME REGION AREA
Length:49 Length:49 Norteast: 9 Min. : 178.2
Class :character Class :character Midwest :12 1st Qu.: 93648.4
Mode :character Mode :character South :17 Median :144954.4
West :11 Mean :159327.3
3rd Qu.:213037.1
Max. :687714.3
total_pop_10 total_pop_15 geometry
Min. : 545579 Min. : 579679 MULTIPOLYGON :49
1st Qu.: 1840802 1st Qu.: 1869365 epsg:4269 : 0
Median : 4429940 Median : 4625253 +proj=long...: 0
Mean : 6162051 Mean : 6415823
3rd Qu.: 6561297 3rd Qu.: 6985464
Max. :36637290 Max. :38421464 Comparing approaches to data frames
| {base} | {dplyr} |
|---|---|
$ |
pull() |
[; subset() |
filter(); slice(); select() |
rbind() |
bind_rows() |
cbind() |
bind_cols() |
aggregate() |
summarize() |
Using base R with attribute data
Subsetting by position
The base R [ operator lets you filter rows or select columns using an integer index:
Subsetting with a character or logical vector
You can also use character or logical vectors:
sf provides a “sticky” geometry column
The geometry column is “sticky” even when you transform the data:
Using comparison operators that return logical vectors
Using comparison operators to filter or subset data is a common approach to answering questions.
Comparison operators
| Symbol | Name |
|---|---|
== |
Equal to |
!= |
Not equal to |
>, < |
Greater/Less than |
>=, <= |
Greater/Less than or equal |
&, |, ! |
Logical operators: And, Or, Not |
Using dplyr with attribute data
Using filter() or slice()
Using select()
Creating new variables
Using <- or =
Using mutate()
Using left_join() or inner_join()
Example to be added!
Chaining functions with pipes
Pipes (%>% or |>) help make data transformation scripts easier to read and understand:
us_states %>%
filter(REGION == "Midwest") %>%
mutate(
total_pop_change_10_15 = total_pop_change_10_15 / 1000
)Simple feature collection with 12 features and 8 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -104.0577 ymin: 35.99568 xmax: -80.51869 ymax: 49.38436
Geodetic CRS: NAD83
First 10 features:
GEOID NAME REGION AREA total_pop_10 total_pop_15
1 18 Indiana Midwest 36157.85 [mi^2] 6417398 6568645
2 20 Kansas Midwest 82254.08 [mi^2] 2809329 2892987
3 27 Minnesota Midwest 84388.99 [mi^2] 5241914 5419171
4 29 Missouri Midwest 69774.95 [mi^2] 5922314 6045448
5 38 North Dakota Midwest 70725.36 [mi^2] 659858 721640
6 46 South Dakota Midwest 77130.41 [mi^2] 799462 843190
7 17 Illinois Midwest 56368.25 [mi^2] 12745359 12873761
8 19 Iowa Midwest 56271.95 [mi^2] 3016267 3093526
9 26 Michigan Midwest 58347.38 [mi^2] 9952687 9900571
10 31 Nebraska Midwest 77325.58 [mi^2] 1799125 1869365
total_pop_change_10_15 geometry total_pop_10_scaled
1 151.247 MULTIPOLYGON (((-87.52404 4... 6417.398
2 83.658 MULTIPOLYGON (((-102.0517 4... 2809.329
3 177.257 MULTIPOLYGON (((-97.22904 4... 5241.914
4 123.134 MULTIPOLYGON (((-95.76565 4... 5922.314
5 61.782 MULTIPOLYGON (((-104.0487 4... 659.858
6 43.728 MULTIPOLYGON (((-104.0577 4... 799.462
7 128.402 MULTIPOLYGON (((-91.41942 4... 12745.359
8 77.259 MULTIPOLYGON (((-96.45326 4... 3016.267
9 -52.116 MULTIPOLYGON (((-85.63002 4... 9952.687
10 70.240 MULTIPOLYGON (((-104.0531 4... 1799.125Tip: Packages to use with pipes
Intermission: Maps and charts with {ggplot2}
The use of pipes is especially helpful with data visualizations where it reduces the need for intermediate placeholder objects or exports.
Intermission: Maps and charts with {ggplot2}
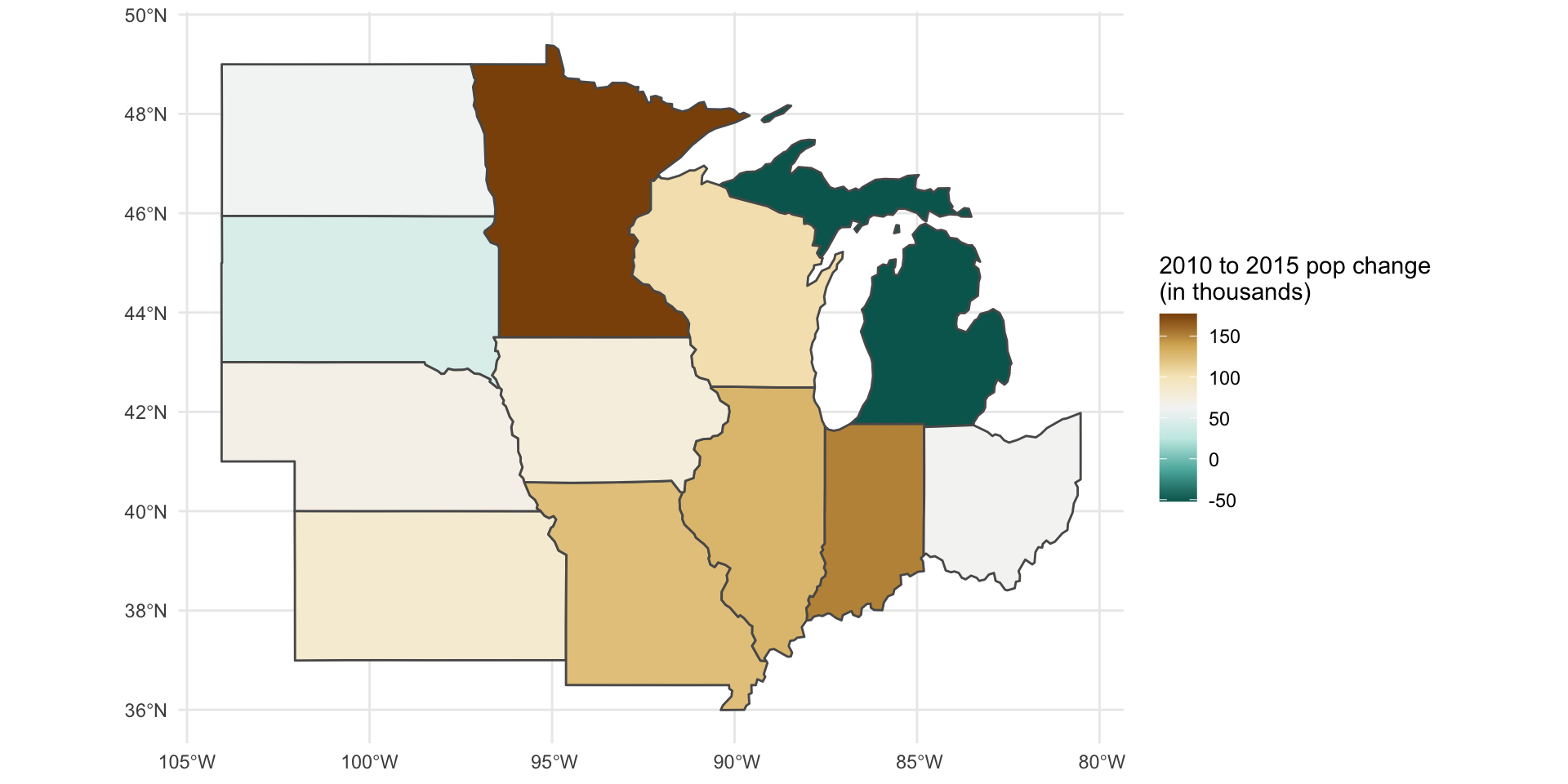
You can also pass functions directly to the data and aesthetic arguments for {ggplot2} geoms:
us_states %>%
arrange(desc(AREA)) %>%
rename(Region = REGION) %>%
slice_head(n = 10) %>%
mutate(
rank = row_number()
) %>%
ggplot() +
geom_sf(aes(fill = Region)) +
geom_sf_label(aes(label = rank)) +
scale_fill_brewer(type = "qual") +
geom_sf(data = us_states, fill = NA) +
labs(title = "10 largest states (by area) in U.S.")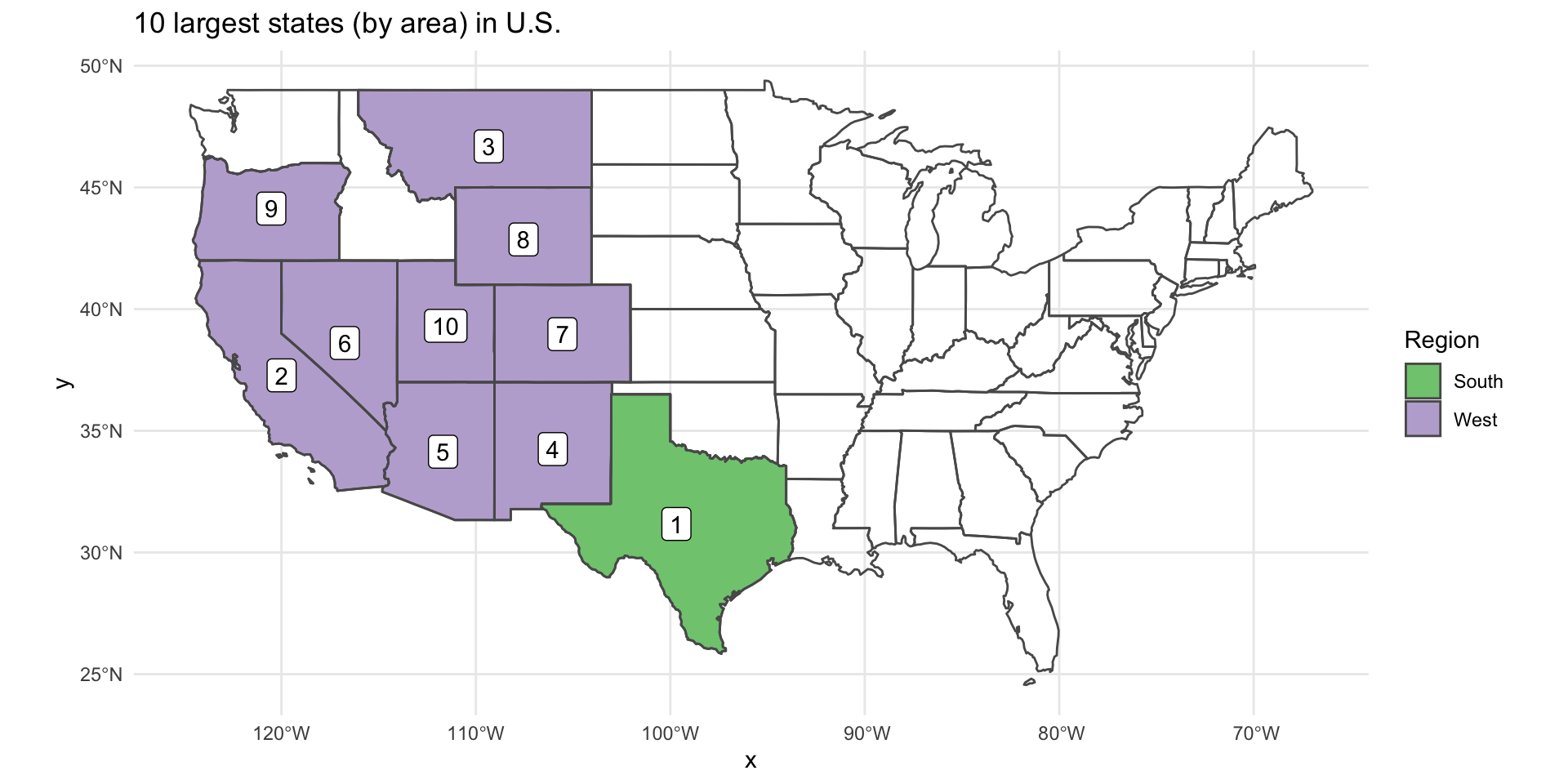
Additional topics
- using SQL queries to filter data
- {stringr} package and using regex
- using
case_when()for recoding variables - using
pivot_longer()to pull variables from column names - date and time variables
Recap on attribute data with R
- base R and dplyr both support many of the same tasks
- use pipes to chain together actions